게링 지기위릿!
나난나난나나
게링 지기위릿!
왓?
ㅋㅋ
사이버대에서 머신러닝과 빅데이터분석 과목을 듣고 있다.
지지난학기에 파이썬 들은게 1도 기억이 안 나서.
이번에 배울 R은 언제든지 빠르게 복귀할 수 있게끔 로그를 남기려 한다.
인스톨:
https://posit.co/download/rstudio-desktop/
Posit
The best data science is open source. Posit is committed to creating incredible open-source tools for individuals, teams, and enterprises.
posit.co

R 깔고 RStudio를 깐다.


기본 파이썬이랑 비슷하다.

툴스 - 글로벌 옵션

디폴트 워크스페이스 설정.
Cmd + N 이 안 먹는다.
(커맨드 오는 먹네)
손수 뉴 알 스크립트 생성.

- 한 줄 실행: 커서 + Ctrl + Enter
- 여러 줄 실행: 드래그 + Ctrl + Enter
- 전체 실행: Ctrl + Alt + R

변수에 값 대입시
= 도 가능하고, <-도 가능하지만
함수 아규먼트란에서 값넣기를 수행하고싶으면
<- 만 가능하다.
약간 unintuitive 하지만 일단 그러려니 하자.

help 치면 터미널마냥 헬프가 나온다.

ㅋ.
내가 OS 만들면 (적어도 플레이버를 만든다면)
이스터에그로 call 넣는다.
call
to whom?
call 119
in Korea? no thanks.
call 191
wtf are you in Europe? in France or something?
call 911
there we go. Whoops dead signal.
call joe
joe who?
call joemama
like I did yours last night?
ㅋㅋ 잡설 그만하고.

펑크션 (대학다닐때 변싱같은 교수샛기 하나가 맨날 펑크션 펑크션 거렸음. 대가리에 펑크난샛기)
저렇게 만든다.
Ctrl + Shift + C -> 주석처리

패키지 설치
install.packages('packageName')
패키지 호출
library(packageName)
패키지 삭제
remove.packages("packageName")
쌍따랑 작은따 구분이 없나보다.
연산자
%/%: 몫
%%: 나머지
**: 제곱 ^도 가능.
나머지는 다른 언어랑 같음.

이렇게 else 내려버리면 안된다.

문장이랑 변수값 어떻게 합치는지 모르겠다.
apply: 벡터/행렬/리스트에서 행/열단위로 연산.

오호
행렬연산 편하넴.
min
median
max
sum
(평균은 뭐지 avr 등등 아무리 쳐도 안 나온다)
lapply: list 로 반환
sapply: 벡터로 반환

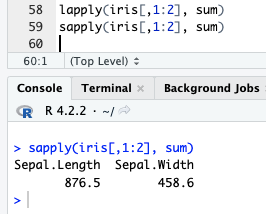
예제 -> 붓꽃 (아이리스) 데이타 쓰기.

연습용 데이터쎗

스트럭쳐로 볼 수 있다.
iris$Sepal.Length
(자동생성 안 뜨면 tab 눌러서 띄우면 된다)
Dataframe vs Matrix: 타입 동일 - 노상관 여부
Factor: enum같은건가? 범주라고 한다.

뷰 를 쓰면 따로 CLI말고 GUI를 띄워주나보다.
앞에 대문자 꼭 박자.

데이터 일부 추출: iris[,1:3]

DB SQL 던지는 것 같다. * 안 박아도 되서 좋다.

ㅇㅎ.
1-2주차 끝.
데이터 분석:
주어진 데이터로부터 인사이트를 찾아내고, 의사결정을 지원하기 위해 데이터를 전처리 / 변환 / 모델링 하는 과정.
e.g. 문장에서 조사 같은 형태소 제거, noun verb adj같은 것만 추출
synonyms 치환 등.
프로시져:
데이터 분석설계 - 데이터 수집 - 데이터 가공처리 - 데이터 분석 - 분석 결과 도출
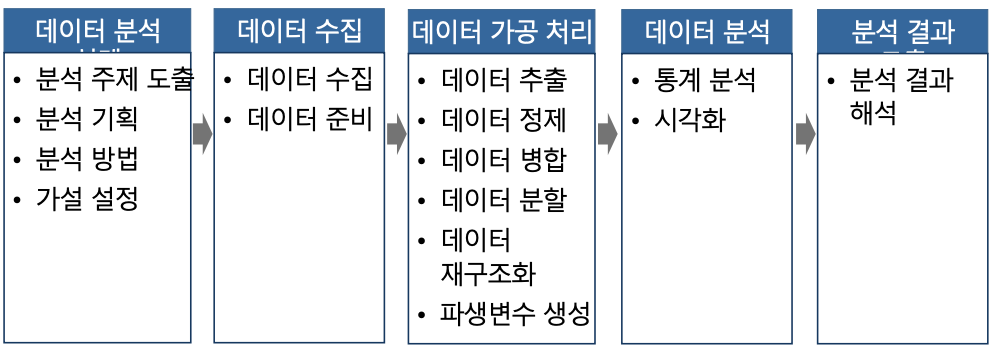
데이터 수집 패키지 : 셀레늄 Selenium
-> beautifulsoup으로 파싱 한다고? 그럼 준비패키지? -> 분석
데이터 병합은 거의 필수.
데이터 재구조화-> python의 pivot, pivot table등
feature engineering: 파생변수 생성,
파생변수: 기존 변수에서 분석 목적에 따라 생성되는 결과변수.
(e.g. 총점, 평균, min, max 등)
통계분석법: 회귀분석, 상관분석...
데이터 수집:
- DB - SQL 던져서
- 다운로드 - data.go.kr, aihub, kaggle.com 가면 많이 볼 수 있음.
- 크롤링
R 자료구조
Row 행: 관측치 (observation) -> 자꾸 raw라고 쓴다 ㅋㅋ 마스터키친 너무 많이 본거같음.
Column 열: 특성 (feature, 간혹 variable이라고 부르기도 함)
Value 값: 행과 열에 들어가는 데이터 (관측값)
- Vector (자꾸 벡터와 스칼라가 떠오른다)
동일한 데이터 유형의 데이터로 구성되어있는 1차원 데이터 구조.
c(1,4,52,5,123,1) -> concatinate의 c
- Factor (요인), Categorical Data (python에서는 카테고리컬을 더 많이 씀)
범주형 데이터
아하. 동적 이뉴머레이션이라고 생각하면 되겠다.
- 행렬 Matrix
동일한 데이터 유형의 2차원 구조의 데이터
- 배열 array
n차원 구조의 데이터 (행렬은 배열의 소집합)
- 리스트 (일반 자료구조의 리스트?)
벡터 행렬 배열 데이프르레임같은 다른 데이터 구조를 모두 묶을 수 있는 가장 유연한 구조
- 데이터 프레임
데이터 유형에 상관 없는 2차원 데이터 구조.
요약:
벡터: 한 가지 데이터 타입, 1차원 구조 데이터
행렬: 한 가지 데이터 타입, 2차원 구조 데이터
배열: 한 가지 데이터 타입, 다차원 구조 데이터
리스트: 여러 데이터 타입, 1차원 구조 데이터
데이터프레임: 리스트를 묶은 2차원 구조 데이터.
데이터 타입:
- 숫자형
- 문자형
- 불린
재밌구만?
to create a Vector
variableName <- c(datum, datum, datum)
mode(variableNaem) -> typeOf internal datum -> 뉴메릭, character, logical 이렇게 나옴
typeof(vN) -> typeOf Datum & Data -> double, character, logical 이렇게 나옴.
str(vN) -> to check structure
length(vN) -> to check length
remove(vN)
rm(vN)
같음.
팩터 만들기

x4 데이터가 인덱스로 들어감.

이렇게 하면 치환으로 작용함
매트릭스 만들기
1차원 벡터를 2차원 행렬로 변환
-> col을 3에서 4로 늘렸더니, R에서 기존의 데이터를 다시 쓰는 방법으로 입혀주고, 에러띄우고 처리 완료
-> 반복 형태로 초기화 하고싶으면 이 방법을 써도 되겠다.

배열 어레이 만들기
array(c(1,2,3,4,5,6,7,8,9,10,11,12), dim=c(2,3,2)) #행,열,깊이
벡터 조혼나 쓴다.
vector: 여러 자료를 때려박으면 하나로 통일시켜버림.
vector1 <- c(1, "str") -> 인티져 1을 캐릭터 '1'로 itoa 해버림.
데이터프레임 만들기.
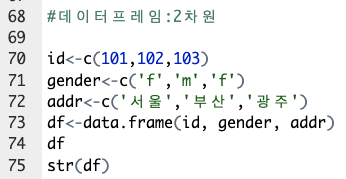
벡터를 빡 빡 박아넣으면 된다.

View를 때려박으면 (앞에 대문자 꼭)
변수명이 보인다.
각 변수명 부분이 features, variables.
같은 거다. 피쳐가 뭐냐 다시 봐야겠다.

딸라 뒤에 피쳐들이 보인다.
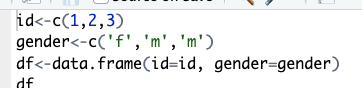
데이터 프레임에 변수명을 줄때는 ''나 '를 안 써도 된다.

앞에 오는게 컬럼명
파일 읽기:
read.table("test_data.txt", header=TRUE)
-> 아이클라우드와 연동된 폴더는 상대 디렉토리가 안 먹는 것 같다. ㅅㅂ
(루트: 디폴트 설정한 디렉토리)
절대 디렉토리 쓸 때 한글 복붙도 안 된다.
wtf.
read.table("test_data_col.txt",col.names = c('id','gender','age','addr'))
이렇게 하면 컬럼명이 없는 데이터도 쓸어올 수 있다.
아두이노같은거로 데이터 잔뜩 쌓아놓고
이걸로 한방에 불러올 수 있겠다.
CSV로 변환하는 프로그램 쓰고 막 안 그래도 될듯.
read.table("test_data.txt", skip = 2,col.names = c('id','gender','age','addr'))
데이터 건너뛰기.
컬럼 헤드 라인도 데이터로 간주하고 skip해버린다.
라인체인지 (\n) 갯수 세고 끝나나보다.
read.table("test_data.txt", header=TRUE, nrows=5)
5줄만 가져오기.
헤더 트루 주면 헤더 뺴고 5줄만 가져옴.
read.table("test_data2.txt",sep=",", header=TRUE)
구분자 지정해서 가져온다.
sep " "가 기본인듯.
read.csv("test_data.csv") (commar seperated v?) csv가 원래 컴마로 구분하는 거였구만.
read_excel("test_data.xlsx")
xmlToDataFrame("test_data.xml")
fromJSON("test_data.json")
다른 파일 가져오기.
(팩키지 따로 설치해야 될 수도 있음)

install.packages("readxl")
library(readxl)
install.packages("XML")
library(XML)
install.packages("jsonlite")
library(jsonlite)
아 제이슨이 딕셔너리 자료구조였구나.
ㅇㅎ.
이제알았네.
리스트로 읽어진다.
tibble: dataframe의 후속 타입.

str(iris)
ncol(iris)
nrow(iris)
dim(iris) #디멘젼
ls(iris) #레이블즈
head(iris) #상위 6건
tail(iris) #하위 6건 (제일 아래)
head(iris,n=20)
데이터셋의 특정 컬럼 보기
iris$Sepal.Length
딸라로 구분

mean(iris$Sepal.Length) #평균
median(iris$Sepal.Length)#중위수
range(iris$Sepal.Length)
quantile(iris$Sepal.Length) #4분위수
quantile(iris$Sepal.Length, probs=0.8) # 몇 퍼센트의 지점 수를 보고싶은ㅈ.
var(iris$Sepal.Length) #분산
sd(iris$Sepal.Length) #표준편차


공학수학 책 다시 꺼내봐야겠다. ㅋㅋ
3주차 끝.
4-5주차
dplyr 팩키지


%>% : 수식을 연결해주는 파이프 연산자
단축키: Ctrl Shift M
-> 작업별로 따로 결과를 저장-입력하지 않고
파이프라인으로 전달해주는 것.
reshape2 (reshape의 성능개선 패키지)
파이썬 판다스의 피벗테이블 등과 비슷함.
melt, cast 함수
결측치
is.na() -> 불리안 리턴
table (is.na()) 빈도 확인
na.rm = T -> 낫 어베일러블 리무브 트루, 결측치 제하고 연산.
na.omit() -> 결측치 행 row 제거 (오밋: 생략. 익스클루드)
변수명[is.na(변수명)] <- 대체할 값 -> 대체함.
vari = c(50, NA, 70, ...)
vari[is.na(vari)] <- 50
이러면 na true만 참조되서 50이 들어감.
이상치
이상치 또는 극단치: 데이터 정상 범주 벗어난 값
boxplot 함수 이용해 확인
기술통계량: boxplot(변수명)$stats
mtcars: 자동차 관련 기본 제공 데이터셋
#filter (data, condition)
filter(mtcars, cyl == 4)
filter(mtcars, cyl == 4 & mpg > 20)
filter(mtcars, cyl == 4, mpg > 20)
앤드도 되고 쉼표도 된다.
# select(dataset, var, var, ...)
select(mtcars, mpg, hp, wt)
# arrange(data, var)
arrange(mtcars, mpg, desc(drat))
# descend로 내림설정, 기본은 오름차순
#mutate (data, addedVar = value)
mutate(mtcars, year_col = "2023")
year_col이라는 속성 생김
rank(mtcars$mpg)
연비 순으로 랭킹 .
#distinct(데이터, 변수명)
mtcars$cyl
distinct(mtcars,cyl)
distinct(mtcars,gear)
중복 제거
#summarise(데이터, 요약할 변수명=기술통계함수)
summarise(mtcars,mean(cyl))
summarise(mtcars,cyl_mean=mean(cyl),cyl_min=min(cyl) ) #요약할 변수명 지정 실_민
summarise(mtcars,mean(cyl),min(cyl) )
민값: 평균값
그룹바이(데이터, 그룹화 기준 열)
gp_cyl<-group_by(mtcars, cyl) #cyl값을 기준으로 그룹화
gp_cyl
# 랜덤 샘플링
sample_n(mtcars, 10)#32건에서 10건
sample_frac(mtcars, 0.5) #32건의 50%
# %>% 기호 사용해서 동일한 연산
mutate(mtcars, mpg_rank=rank(mpg)) %>%
arrange(mpg_rank)
빠이프
library(readxl)
exdata1<-read_excel("/Users/chico/Documents/Programme/R/4thWeek/Sample1.xlsx")
exdata1
exdata1 %>%
select(ID)
exdata1 %>%
select(ID, AREA)
exdata1 %>%
select(-AREA)
exdata1 %>%
select(-ID, -AREA)
#셀렉트, 파이프로 데이터는 바로 먹혔고
#ID는 ID 속성만, -AREA는 에리어 속성 뺴고 등
하... 너무 지루하다.
미칠거같다.
함수만 자꾸 나오고
원리같은거 없고
그냥 달달달 외우라는데. ㅅㅂ.
무슨 역사 수업 듣는거같음.
앞에서 설명했던거 또 설명하고 또 하고 또 하고 또 하고 또하고
지난시간에 했던것도 또 설명하고
차라리 과제를 던져주든가...
배우는 사람은 하는거 없이
그냥 혼자 떠드니까
한 주 지나면 기억이 하나도 안 난다.
그래놓고 중요하니까 연습 많~~이 하세요 하는데
니 알아서 해라 임마! ㅋㅋ; 강의 별로다.
그냥 떠드는거 봐야겠다.
#데이터 재구조화
# reshape2
# melt함수 : 열이 긴 데이터 -> 행이 긴 데이터
# cast변수 : 행이 긴 데이터 -> 열이 긴 데이터
boxplot(mtcars$wt)
boxplot(mtcars$wt)$stats
#[,1]
#[1,] 1.5130 #최저 이상치 경계
#[2,] 2.5425 #1사분위(25%)
#[3,] 3.3250 #중위수(50%)
#[4,] 3.6500 #3사분위(75%)
#[5,] 5.2500 #최고 이상치 경계
4th Avril 2023
아 이 교수님 말투도 이제 거슬리기 시작한다.
자기딴에는 발음 정확하게 한다고 하는 것 같은데
(그래 "프" [p] 가 아니라 그래[f] 이런 식으로)
자꾸 레이블 (Label)을 Rabel 로 읽질 않나
한국식 발음으로 덮어버리는 것도 많고 (Th발음 등)
초성의 f는 여전히 p로 발음하고
모음의 경우 발음 강도 길이 등등 모두 그냥 한국인...
그와중에 전라도 말투 (~~ 으)까지 섞여 나오니까
진짜 거슬린다.
그냥 일관성있게 한국 말투로 읽으라고.. 짜증.ㅋㅋ
히스토그램도 희스토그램이라 그러고 ㅋㅋ
ggplot2 패키지를 이용해서 시각화에 대해 배웠다.
패키지만 주구장창 떠드니까 별로 효용이 없는 것 같다.
아직까지는...
괜히 들은 것 같다 ㅜㅜ
팩키지 한 두어주차에 쫙 몰아서 설명해주고
예시 펑션만 자료로 던져주고
과제 몰빵해주고
통계학적 이론같은걸 좀 더 설명해주면 안되나.
이해가 안되는구만.

딸라 표시로 열 이름 고르면 그 데이터만 나옴...
R은 언어가 아니고 스크립트인건가
너무 (컴퓨터공학 기준) 비전문가용 툴같은 기분만 든다.
데이터 다룰 때 편하긴 하겠네
그래서 데이터용 스크립트..
글자로 치는 엑셀
좋구만.
CLI for SS (spread shite, 펴바른 분변)
ㅋㅋㅋㅋ
스프레드 pp도 스프레드.
막상 생각해보니 스프레드(펴바르다)의 과거형이랑 PP형이 뭐지?
스프로드? 스프로든? 하면서 생각이 안 났는데
막상 보니 스프레드-스프레드-스프레드
글쿠만.
이번에 '드디어' 과제가 나왔다.
단순 시각화...

풀 사이즈 리포트 형식 에세이를 쓰는 것도 아니고
그냥 이미지 몇개 던지면 된다.
무슨...
이래서 뭘 배우겠음...
여튼.
data.go.kr에서 받은 파일이 안 열린다.
테이블에 레이블들이 한글로 되어있는데,
윈도에서 작업하면 기본값이 UTF-8 인코딩이 아니다보니 (EUC-KR)
못 읽는다.ㅜㅜ
read.csv("/Virtual_Directory/Police_Regional_Crime_Records_20151231.csv", header = T, fileEncoding = "euc-kr")


악취유인은 무슨 범죄여 ㅋㅋㅋㅋ
냄새나는곳에 유인했다고?ㅋㅋㅋㅋㅋ
아 약취...

출처:
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=lawme1006&logNo=220766556061
인신매매나 납치 같은거구만.
지역별로 대분류 범죄 막대그래프랑
대분류별 범죄 중분류 파이차트같은걸 그려서 던져야겠다.
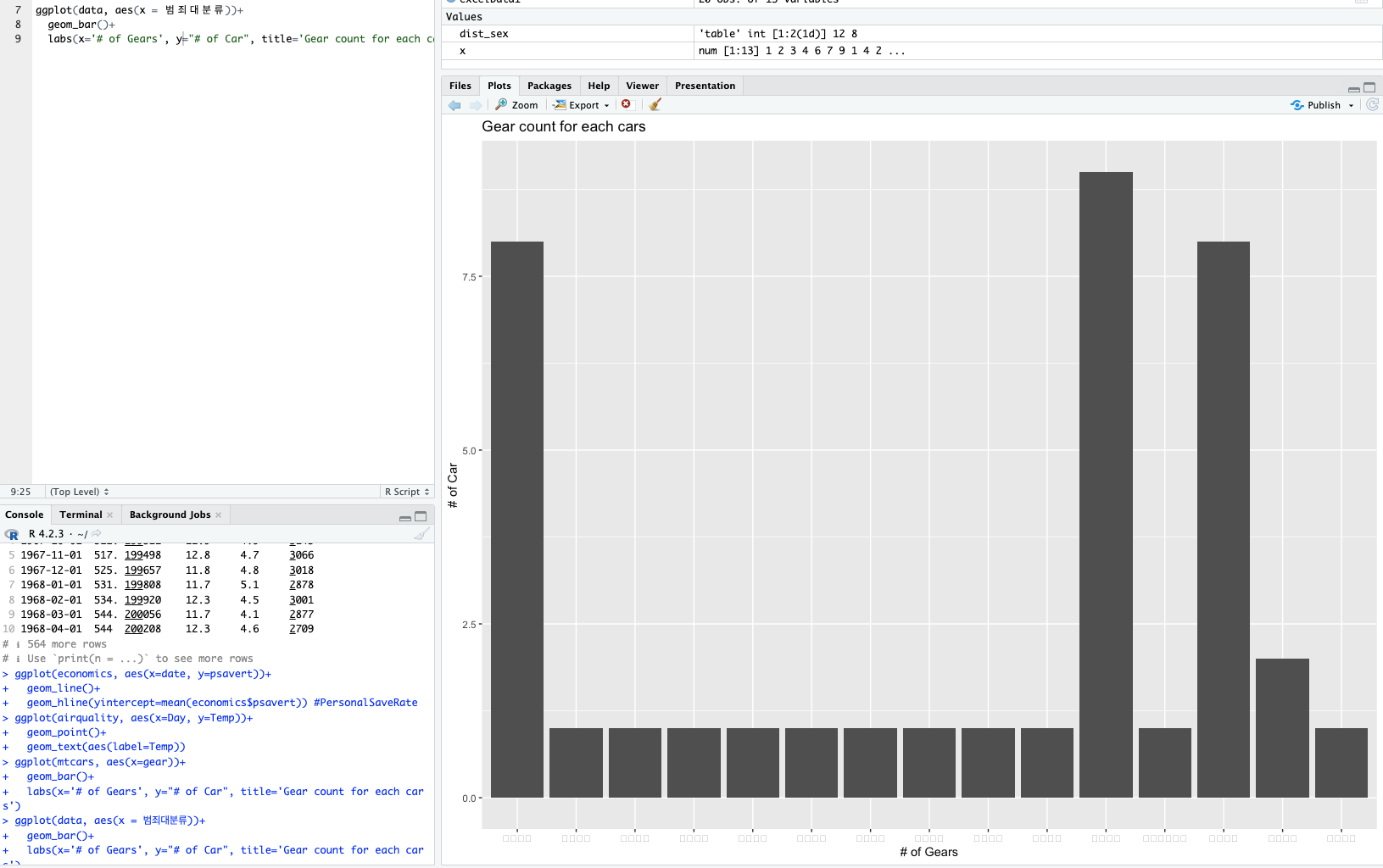
한글이 줴다 깨져나온다.ㅜㅜ

Numbers로 여니 깨져 나온다.
하하... 그지같네.
R에서 View로 GUI를 띄운 다음에
Excel을 띄워서 복붙. 저장.
휴.
그래도 깨진다.
아 진짜 그지같네.

일단은 엑셀에서 데이터를 매니퓰레이트 하고 있다.
강력범죄 - 중범죄 (Felony)
지능범죄 - WhiteCollar
폭력범죄 - Violent
교통범죄 - Traffic
으로 바꿨다.
안되면 미국 데이터 받아서 처리하지 뭐.

영어는 안 깨지고 잘 나온다.
망할거... 근데 왜 소수점으로 나오는거지???
...
어떻게 어디서부터 해야될지 감이 안 온다.
기존 데이터에서
대분류 + 특정 지역 범죄 건수만 뽑아서
대분류 범죄별로 건수 막대그래프를 그리고 싶다.
어떻게 하는지 1도 모르겠다.
망할 강의.
실습 하나 없이 (사이버니까 과제 형태로 해야겠지?)
자기 혼자서 떠들기만 하고
그냥 이렇게 쓰시면 이렇게 결과가 나와요~ 하는데
그럼 응용을 어떻게 하냐는거냐고.ㅅㅂ.
내 등록금 겁나 아까워 죽겠네.

자료 찾기가 더 빡세서
그냥 만들었다.
만들고 나니 동일한 타입이 섞여있네...
ㅅㅂ...
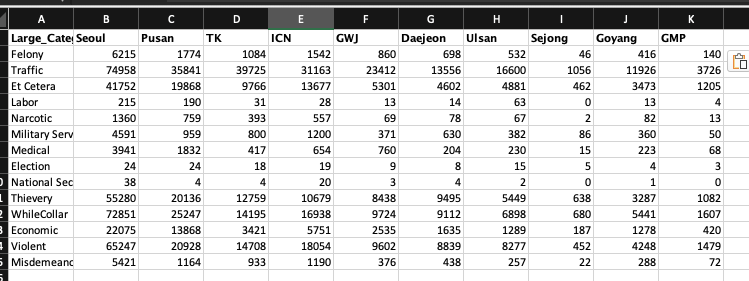
R보다 엑셀이 익숙해서
Sumif로 대충 계산하고
복붙해서 새로 만들어 주었다...
툴이 있어도 쓰질 못하는 그지같은 현실..ㅋㅋ ㅜㅜ
지피티 형님한테 물어봐야겠다.

영어만 할 줄 알면 교수님한테 물어볼 필요 없이
피티형한테 물어보면 된다.

흠.
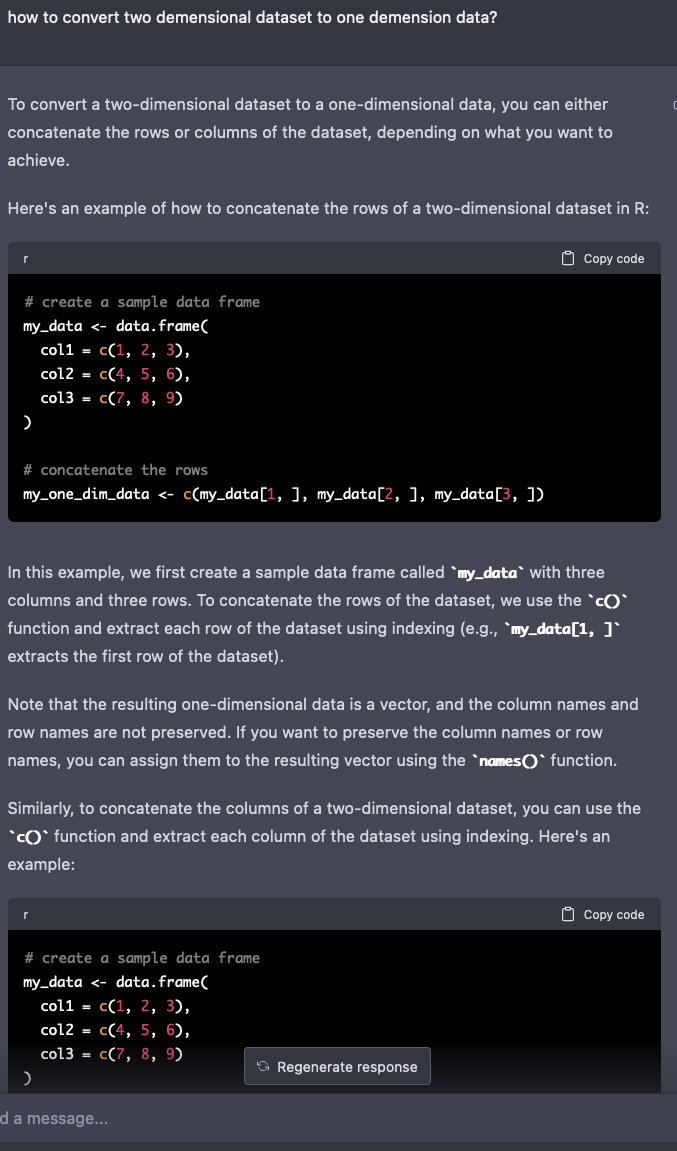
일단 2차원 데이터를
1차원으로 바꿔야 뭔가를 할 수 있을 것 같다.

이런식으로.
헤더 (지역명 [서울, 부산,.... ] 이랑 카테고리 [펠로니, 바이올런스, 화이트컬러,...])를 하나만 잡고
나머지 카테고리는 일반 데이터로 (중복되게) 데이터 셋으로 넣어주는게 필요한듯.
씨부엉 교수님은 이런거 안가르쳐주고
짜증.
일단 범주를 범죄종류로 잡고
지역을 데이터값으로 넣자.

피티형이 엄청 도움이 많이 된다.
스파씨바 오촁머치.
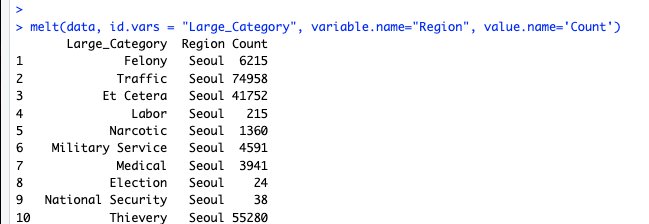
melt를 써볼까.

내가 원한게 이거시었어!!!!! ㅜㅜ
비싼 등록금 내고 듣는 망할 대학 강의보다
무료 인공지능이 훨씬 도움이 된다.

ㅋㅋㅋㅋㅋㅋ
피티형이 코칭을 계속 해주는데
아직 잘 모르겠어서
아까 보여준 예제 세트로 해달라 그랬다.

앞뒤 문맥 알아먹는 대화식 AI 최고다
피티형 만세.

피티형!!
제가 해냈어요!!
moltenData <- melt(data, id.vars = "Large_Category", variable.name="Region", value.name='Count')
moltenData
crime_Seoul <- subset(moltenData, Region == "Seoul")
crime_Seoul
barplot(crime_Seoul$Count, names.arg = crime_Seoul$Large_Category,
xlab = "Type of Crime", ylab="Total Number of Crimes",
main = 'Crimes in Seoul')
ㅋㅋㅋㅋㅋㅋㅋㅋ 하... 그지같네.
Melt 함수와 Subset 함수의 중요성을 깨달았다.
ㅅㅂ
형 그럼 파이함수는 어떻게 쓰는거임?
교수님이 준 예제로는 안되는데?

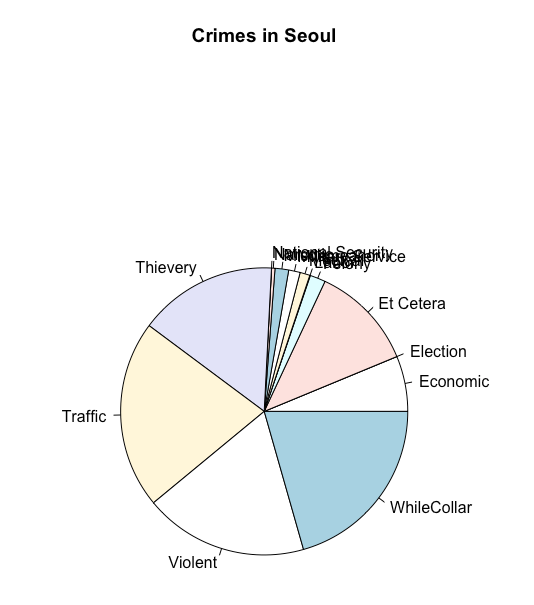
형 근데 글자가 겹쳐

와 진짜 고마워 형.

형 그래도 겹치는데
아예 옆에 나열할 수는 없는거야?

아 저걸 레전드라 그래?
형이 레전드지.
ㅋㅋㅋㅋㅋㅋㅋㅋ

레이블 지저분한데 없앨 순 없어?



형.
진짜 최고다.
이제 지역/범죄종류 별 막대그래프 통합을 그려보자.

ㅋㅋㅋㅋㅋㅋㅋㅋ
형은 열심히 코딩해주고 있고
나는 오로라 영상 보고 있다.
어어 벌써 다 짰단 말이야
아 좀 복잡한데.


ㅋㅋㅋㅋㅋ형 최고야.

아니 형.
지역별로 그려야지.

잘했어
쿨러팡팡.
소스코드도 제출할 필요 없고
사진만 (그것도 한 장만 가능) 덜렁 제출하는
반쪽짜리 실습이지만
이런 과정이 있어야 손에 익지..
참 사이버대는 별로다. 이럴 때 보면 볼수록.
'1.A. High Level Computing > SW Language Specifics' 카테고리의 다른 글
| [토막글] C언어 연산자 설명 & 예시 ( /, +=, ++, () ? : , ...) (0) | 2023.03.14 |
|---|---|
| [토막글] Java UI띄우기 (Swing) (0) | 2023.02.22 |
| [토막글] Eclipse에서 Java 프로젝트 만들기 (macOS) (0) | 2023.02.22 |


Comment(s)